안녕하세요, 오늘은 몇일 전 Meta에서 발표한 DINOv2 논문을 소개하려고 합니다. Computer Vision 분야에서 이미 유명한 DINO를 업그레이드 해서 발표했는데요, 이 Self-supervised Learning 방식은 어떻게 탄생했는지, 어떤 구조와 장점을 갖는지, 그리고 그 결과는 어떤지 리뷰하도록 하겠습니다.
Introduction
Meta, Google, OpenAI와 같은 거대한 기업에서는 요즘 Foundation models 연구에 한창인 것 같습니다. NLP에서는 GPT가 득세하고 많은 대중들의 사랑을 받았는데요, Computer Vision에서는 어떤 모델이 있을까요?
Radford et al.과 같은 연구들이 있었지만 이 방식들은 모두 Text-guided Pre-training을 채택했습니다. 하지만 이 방식은 두가지 큰 문제가 있습니다.
- 텍스트에는 주요한 정보(Rich information)만 포함되기 때문에 Pixel-level information은 학습이 되기 어렵다
- Image encoder가 늘 텍스트를 필요로 하기 때문에(aligned text-image corpora) 이미지 단독으로 학습할 수 없다
그럼 텍스트 없이 학습을 시도한 연구는 없을까요? 물론 있었습니다만 그 연구들의 문제는
- 데이터셋이 너무 작았거나(ImageNet-1k)
- 데이터셋의 품질이 많이 떨어진다 (Uncurated)
그래서 DINOv2에서는 다 준비했습니다.
- iBOT과 같은 Image / Patch Level Discriminative Self-supervised Learning(SSL)
- Image level은 서로 다른 이미지를 다르다고 구별하는 작업
- Patch level은 이미지 내 서로 다른 patch들을 구별하는 작업
(달라서 다른건데 그걸 학습한다고? 효과가 있니? 라고 물어보면 네 있습니다) - 한마디로 iBOT에다가 뭔가를 덕지덕지 붙였다
- 방대한 양의 정제된 데이터셋
- 142M의 데이터셋
- 메모리 사용을 줄이면서도 빠른 학습 기법
- 2배 빠르면서도 메모리는 3배 적게 쓴다
잠깐 Patch-level 학습의 결과물을 보면

위의 그림과 같이 patch-level로 PCA를 분석했을 때 객체의 요소요소를 유의미하게 분류하는 것을 확인할 수 있습니다. 이게 무슨 말이냐면 독수리가 있으면 독수리의 날개, 몸통, 머리가 서로 다른 색으로 나뉘는 것을 볼 수 있습니다. 이것이 바로 모델이 대상을 의미론적으로 이해했다(Semantically understand)고 볼 수 있는 근거입니다.
그럼 지금부터 DINOv2에서 무엇을 했는지 살펴보겠습니다.
Methods
위에서 언급했듯이 Foundation models이라 부른다면 그에 걸맞는 데이터셋과 모델이 필요합니다.
Data Processing

논문의 Table 15를 보면(in Appendix) 다양한 데이터셋으로부터 긁어 모아 총 142M의 데이터를 모았습니다. 논문에서는 이것을 LVD-142M 데이터셋이라고 부릅니다. 만든 과정은 아래와 같습니다.
- Collecting raw images: 인터넷에서 이미지를 열심히 모읍니다. 불건전 이미지들을 포함해 뺄 거 빼고 총 1.2B개의 이미지를 수집합니다. 이렇게 모은 이미지들이 uncurated data입니다.
- Deduplication: Copy detection을 통해 중복되는 이미지들을 열심히 제거합니다. 중복이거나 중복에 한없이 가깝거나 모두 제거합니다.
- Self-supervised image retrieval: 이제 인터넷에서 모은 uncurated data에 대해 curation을 해줄건데요, 과정은 아래와 같습니다.
- Curated / Uncurated 모두 ViT-H/16 모델을 통해 embedding을 뽑아줍니다.
- Uncurated data에 대해 K-mean clustering을 수행합니다.
- 각 Curated 데이터에 대해 가장 가까운 \(N\)개의 uncurated data를 고르거나 아니면 가장 가까운 cluster를 찾고 그 안에서 \(M\)개를 고릅니다.
- \(N\), \(M\)은 선택된 이미지들을 눈으로 직접 보면서 그 퀄리티에 따라 적절히 조정해 나갑니다.
이렇게 해서 총 142M개의 이미지를 얻었습니다. Curated data는 아까 말한대로 각기 다른 알려진 데이터셋을 모은 것인데, 데이터셋에 따라 as is(그냥 curated data 원본), sample(가장 가까운 데이터 찾기), cluster(가장 가까운 클러스터에서 샘플링) 방법 중 택했고 그 내용은 Table 15를 확인하시면 되겠습니다.
Discriminative Self-supervised Pre-training
DINOv2 모델 자체는 정말 다양한 방법들을 도입해서 성능을 끌어올렸다고 합니다. 마치 몸에 좋다는 한약재를 몽땅 넣어 만든 한약같습니다. 이와 비슷한 느낌으로 YOLO 시리즈가 생각납니다. DINOv2를 설명하기 전에 DINO 구조부터 첨부합니다.

Image-level objective
Knowledge Distillation 방법을 활용합니다. 사이즈가 크고 잘 학습되어 있는 Teacher와 그보다 작은 사이즈(실제 학습해야 할) Student 모델 사이의 distillation을 Cross-entropy loss를 이용해서 합니다.
Patch-level objective
Student에 넣는 이미지는 몇개의 패치를 마스킹하고, Teacher에는 마스킹 없이 넣어 나오는 결과를 Patch-wise하게 Cross-entropy를 계산합니다. 대충 아래와 같은 그림으로 이해하시면 될 것 같습니다.

그림에서는 이해를 돕기 위해 하나의 패치만 표시했지만 실제로는 더 많은 Masked patch가 존재합니다.
Untying head weights between both objectives
Weight tying이라는 개념이 생소하신 분도 계실 것 같아 설명을 드리면, 아까 위에서 Image-level, Patch-level 모두 cross-entropy를 계산한다고 했죠? cross-entropy를 계산할 때 쓰이는 tensor를 얻기 위해 몇개의 레이어로 구성된 head가 있을 것입니다. 그 head를 두 objectives가 서로 공유해서 쓴다는 뜻입니다.
Sinkhorn-Knopp centering
SwAV라는 논문에서 제안되었던 Sinkhorn-Knopp BN를 Teacher softmax-centering 대신 도입했다고 합니다. Teacher-Student domain gap을 좁히기 위한 방법인 듯 하지만 잘 이해하지는 못했습니다.
KoLeo regularizer
논문에서 소개되는 내용으로는 batch 내 여러 feature가 있으면 그 feature 사이의 거리를 최대한 균등하게 만드는 방법입니다. 물론 서로의 위치 관계는 바꾸지 않으면서 수행합니다.
Adapting the resolution
기존 많은 이미지 연구를 생각해보면 \(224\times224\) 사이즈가 많았습니다. 하지만 원본 이미지의 해상도가 큰데 이렇게 작게 리사이즈 하게 되면 작은 물체는 사라져서 보이지도 않습니다... 그래서 이 논문에서는 \(518\times518\) 사이즈도 도입을 했는데 아무래도 메모리도 많이 먹고 시간도 오래 걸리기 때문에 처음부터 이 해상도로 하는 것은 아니고 Pre-training 후반부에 잠깐 이 사이즈로 학습했습니다.
이렇게 많은 방법들을 다 적용하고 나니 성능이 많이 올랐다고 합니다. 이것을 알기 쉽게 정리한 표가 논문에 있습니다.
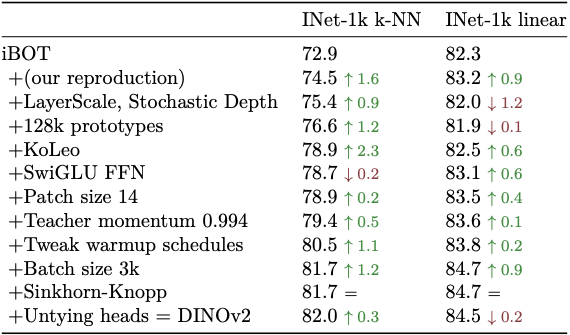
Efficient Implementation
모델 구조를 떠나 학습 방법에도 다양한 옵션이 존재합니다. 하지만 전부 일일이 소개하기는 글이 너무 길어져서 아주 짧게만 소개하도록 하겠습니다. 자세한 내용은 가능하다면 추후 업데이트 하도록 하겠습니다.
- FlashAttention: 메모리와 속도를 개선한 Self-attention이라고 합니다.
- Nested tensors in Self-attention: 서로 다른 패치수를 가진 경우에도 global crop, local crop을 동시에 forward pass 할 수 있는 방법을 적용했다고 합니다. 덕분에 빠르게 학습이 가능합니다.
- Efficient Stochastic Depth: Residual 방식은 정말 많은 네트워크에서 채택하고 있는데, 샘플링을 통해 일부 residual connection을 제거하는 방식을 도입했습니다. 약 40%정도 제거했다고 하는데 이게 효과가 좋다고 합니다.
- Fully-Sharded Data Parallel (FSDP): PyTorch의 DDP를 알고 계신다면 이해가 쉬울 것 같습니다. DP, DDP에서는 마스터 노드(보통 0번 GPU)의 GPU Memory에 의존적인데 FSDP는 전체 GPU의 메모리를 충분히 활용할 수 있습니다 (기존에는 bounded by a single GPU but by the total sum of GPU across compute nodes).
- Model Distillation: 위에서 distillation 이야기를 많이 했었습니다. 그 적용 방안으로 처음에는 가장 큰 버전(ViT-g)을 학습하고, 그 다음부터 학습하는 보다 작은 모델들은 이것을 Teacher network 삼아 학습하게 됩니다. 그렇게 해서 작은 모델에서도 좋은 성능을 낼 수 있게끔 했다고 합니다.
Results
역시 데이터의 힘은 위대하고 갖가지 좋은 방법을 다 도입한 노력은 결실을 맺기 마련입니다.

Self-supervised Learning 만으로도 Weakly supervised 방법을 능가하는 모습을 보여줬습니다. 심지어 모델 사이즈는 동일하고 텍스트의 힘은 빌리지도 않았습니다. 개인적으로는 DINOv2가 어떤 혁신적인 새 방법을 제안했다고는 생각하지 않지만 모델 사이즈와 속도 등을 포함한 모든 방면으로의 개선 노력이 있었다는 점은 정말 박수쳐주고 싶습니다.
위의 task 말고도 Video Classification, Instance Recognition, Segmentation, Depth estimation에서도 기존 모델을 압도하는 결과를 보여줬습니다.

'기술 이야기 > 논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] IMAGEBIND: One Embedding Space To Bind Them All (2) | 2023.05.11 |
|---|---|
| [논문 리뷰] Track Anything Models(TAM) 리뷰 (2) | 2023.05.05 |
| [논문 리뷰] VideoMAE - Masked Autoencoders are Date-Efficient Learners for Self-supervised Video Pre-Training (0) | 2023.04.18 |
| [논문 리뷰] Consistency Models 리뷰 (4) | 2023.04.13 |
| [논문 리뷰] Segment Anything 설명 (코드 살짝 포함) (5) | 2023.04.09 |




댓글