안녕하세요, 오늘은 따끈따끈한 Meta의 논문 - Segment Anything에 대해서 소개하고자 합니다! 데모만 하고도 너무 두근거렸는데 그 이유는 제가 회사에서 하는 일과 관련이 매우 높기 때문입니다. 제가 직접 개발했다면 얼마나 좋았을까 하는 마음도 들지만 이렇게 리뷰라도 할 수 있어 참 행복합니다
- 논문 링크: Segment Anything
- 깃허브 링크: Segment Anything Github
그럼 리뷰 시작하겠습니다
Introduction
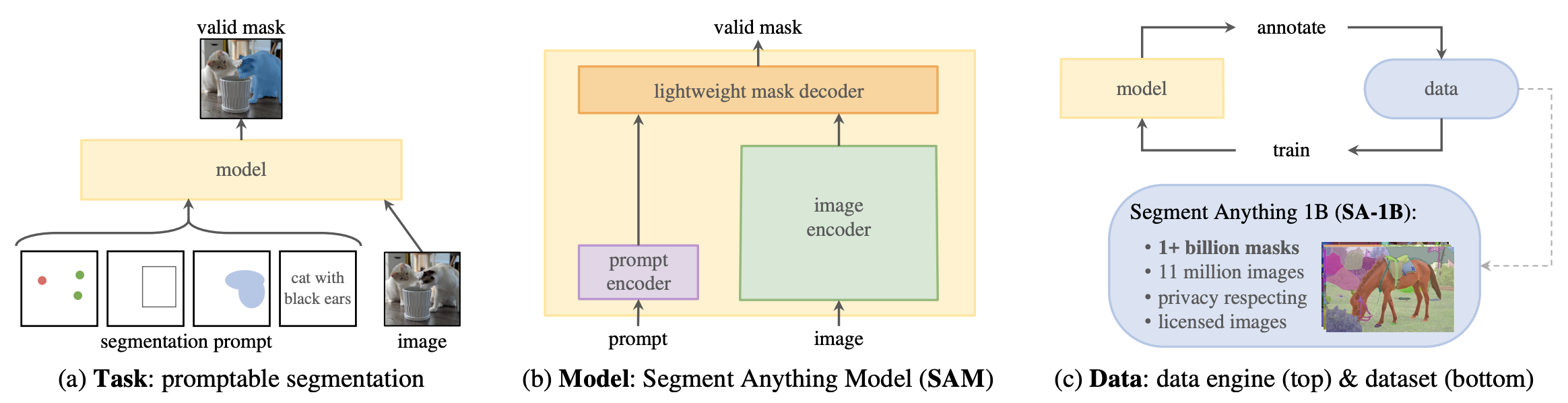
다들 "Foundation models"이라고 들어보셨나요? 분야를 막론하고 거대한 데이터셋으로 Pre-training 시킨 거대한 모델을 foundation model이라고 부릅니다. 이 모델들은 해당 task에 대해 엄청난 generalizability를 보여줍니다. 한마디로 방대한 이해도를 갖춘 모델이라고 말할 수 있습니다.
이 논문의 목적은 Foundation model for Image Segmentation입니다. 이게 무슨 뜻이냐면 모델이 학습하지 않은 물체도 가능하게 하는 zero-shot이라는 뜻입니다.
최근의 시리즈들이 그러했듯, 필요한 준비물이 있는데 그건 바로 Task, Model, Data 입니다. 이와 관련해서 저자들이 한 질문은 아래의 세가지입니다.
- What task will enable zero-shot generalization?
- What is the corresponding model architecture?
- What data can power this task and model?
Segment Anything Task
우리는 ChatGPT를 Prompt 기반의 모델이라고 부르죠. 사용자가 뭔가를 주문하면 그에 맞게 아웃풋을 낸다는 의미에서 그렇습니다. 혹시 Segmentation도 그렇게 할 수 있을까요?
Prompt의 종류에는 여러가지가 있는데 여기서는 점(point), 박스(box), 그리고 텍스트(text)를 입력으로 받을 수 있게 설계했습니다. 사실 pointing 방식의 segmentation은 아주 새로운 접근은 아니었습니다. Deep Extreme Cut(DEXTR), RITM, FocalClick 같은 연구들을 Interactive Segmentation이라고 부르며 하고 있었습니다.
Segment Anything Model
이러한 거대 모델의 특징은 하나같이 강력한 encoder를 갖고 있다는 것입니다. 그렇게 대단한 인코더를 거치고 나면 뒷부분은 상대적으로 가볍습니다. 이 논문에서 명명한 모델의 이름은 SAM(Segment Anything Model)인데, 크게 3가지 요소로 이루어져 있습니다.
- Powerful Image Encoder
- Prompt Encoder
- Mask Decoder
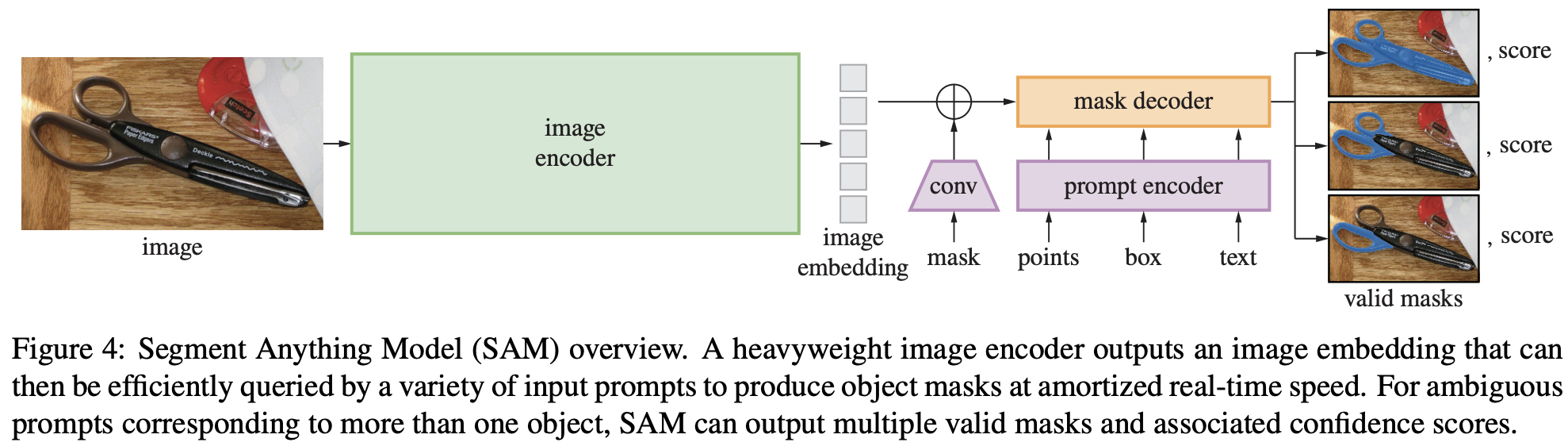
Image encoder에 비해 Prompt encoder와 Mask decoder는 아주 가벼워서 웹에서도 50ms 이내로 동작한다고 합니다! 어떻게 이렇게 대단한지 아래에서 좀 더 보겠습니다
Segment Anything Data
데이터셋을 말하기 전에 먼저 Data Engine을 언급할 필요가 있습니다. GPT야 인터넷에 널린게 텍스트지만 Segmentation에 필요한 마스크는 구하는게 쉬운 일이 아닙니다. 그래서 Data Engine을 만들었는데, 이것도 3단계로 구성되어 있습니다.
- Assisted-manual: 작업자가 점을 찍으면 SAM 모델이 어느정도 마스크를 만들어줍니다. 이렇게 도와주면서 레이블링 합니다.
- Semi-automatic: 특정 object 집합에 대해 SAM이 알아서 마스크를 만들면 동시에 작업자가 다른 object에 대해 마스크를 만듭니다. 예를 들면, SAM에게 "Generating masks for all apples in an image"라고 말하면 얘가 사과 마스크 만들고 있을 동안 사람이 다른 애들을 작업하는 겁니다.
- Fully automatic: 이미지에 grid point를 찍어서 모든걸 알아서 masking하게 됩니다.
특히 Fully automatic을 그림으로 표현하면 이런 과정입니다.
 Input Image |
 Regular grid |
 Output mask |
Fully automatic은 살짝 수정이 필요하지만 그래도 훌륭합니다!
이렇게 해서 어마어마하게 많은 데이터를 수집할 수 있었다고 합니다. 무려 1B masks from 11M images
Segment Anything Method
아까 모델은 세개의 component로 구성된다고 설명했습니다. 하나씩 설명해보면
Image Encoder
Masked Autoencoder(MAE) pre-trained ViT를 사용했습니다. 해당 모델의 우수성은 이미 입증되었기 때문에 굳이 더 언급할 필요 없을 것 같습니다. 이미지가 들어오면 Image encoder를 거쳐 embedding을 얻게 됩니다. 이후에 어떤 작업을 하던, 여기서 Image encoder의 역할은 끝납니다.
Prompt Encoder
Prompt에는 두가지 종류가 있습니다. 각 종류와 그것들이 어떻게 만들어지는지 살펴보면,
- Sparse prompt
- 점(points): Positional encodings summed with learned embeddings
- 박스(boxes): Positional encodings summed with learned embeddings
- 텍스트(text): CLIP output
def _embed_boxes(self, boxes: torch.Tensor) -> torch.Tensor:
"""Embeds box prompts."""
boxes = boxes + 0.5 # Shift to center of pixel
coords = boxes.reshape(-1, 2, 2)
corner_embedding = self.pe_layer.forward_with_coords(coords, self.input_image_size)
corner_embedding[:, 0, :] += self.point_embeddings[2].weight
corner_embedding[:, 1, :] += self.point_embeddings[3].weight
return corner_embedding
sparse_embeddings = torch.empty((bs, 0, self.embed_dim), device=self._get_device())
if points is not None:
coords, labels = points
point_embeddings = self._embed_points(coords, labels, pad=(boxes is None))
sparse_embeddings = torch.cat([sparse_embeddings, point_embeddings], dim=1)
if boxes is not None:
box_embeddings = self._embed_boxes(boxes)
sparse_embeddings = torch.cat([sparse_embeddings, box_embeddings], dim=1)- Dense prompt
- 마스크(Mask): Image embedding에 convolution 수행
self.mask_downscaling = nn.Sequential(
nn.Conv2d(1, mask_in_chans // 4, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans // 4),
activation(),
nn.Conv2d(mask_in_chans // 4, mask_in_chans, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans),
activation(),
nn.Conv2d(mask_in_chans, embed_dim, kernel_size=1),
)
코드는 그래도 길이가 있어 전부 발췌하지는 못하고 일부 발췌했습니다. 출처는 여기입니다.
Mask decoder
여기는 Image embedding과 prompt embedding을 받아 마스크를 예측하는 부분입니다. 기본적으로 Transformer decoder block에 Prompt Self-attention과 Cross-attention을 양방향으로 활용했다고 합니다 (양방향의 의미는 Prompt-to-image, Image-to-prompt입니다). 왜 양방향이냐면 Image embedding, Prompt embedding 모두 업데이트 해야 하기 때문입니다.

이 모델이 Prompt에 따라 Interactive하다는 사실을 계속 기억하시면 됩니다.
그 후 이미지 사이즈에 맞게 upsampling을 수행하고 각 픽셀에 대해 마스크 포함 여부를 판단합니다.
중요한 점은 레이블을 생성하지는 않습니다! 단지 마스크를 만들어줍니다.
Resolving Ambiguity
그런데 우리가 점을 찍으면 해당 점이 가리키는 마스크는 유일할까요? 무슨 말이냐면 사람 손톱이 있는 픽셀에 점을 찍었을 때, 이게 정확히 그 손톱을 얻고 싶은건지, 손을 얻고 싶은건지, 아니면 그 사람 전체의 마스크를 얻고 싶은건지 알기 어렵습니다. 보통은 여러개의 마스크 후보를 얻으면 각 픽셀의 Confidence를 평균내어 단 하나의 마스크를 얻게 되는데요, 이렇게 되면 마스크에 노이즈가 많이 끼고 사람이 얻고자 하는 마스크를 올바르게 내어주기 어렵습니다.
그래서! 논문에서는 3개의 마스크 후보를 주고 (3개 정도면 딱 적당하다고 합니다) 그 중 minimum loss를 갖는 마스크에 대해 학습(backprop)한다고 합니다.

Losses and Training
위에서 minimum loss를 갖는 마스크에 대해 학습한다고 했죠? 이 논문에서 loss는 focal loss와 dice loss(Appendix A.2 참고)의 linear combination으로 구성됐습니다.
- Focal loss는 더욱 어려운 객체에 대해 가중치를 주어 학습한다는 개념이며
- Dice loss는 잘 알고 있는 IoU 보다 조금 더 recall에 집중한 개념입니다. IoU보다 GT를 얼마나 많이 포함했는가를 보는 함수입니다.

SA-1B Dataset
이 논문에서 또 중요한 포인트가 task, model 이외에 데이터가 있습니다. 이미지의 라이센스, 개인정보 등은 차치하고...
SA-1B(Segment Anything-1B) 데이터셋을 소개합니다.
- Images: 사진사가 찍은 11M개의 고해상도 이미지를 모았습니다. 평균 해상도는 무려 3300x4950
- Masks: 위의 이미지에서 1.1B개의 mask를 얻었는데, 그 중 99.1%가 fully automatic 방법으로 얻은 것이라고 합니다. 과연 퀄리티가 어떨까요?? 약 500장을 샘플링해서 전문가에게 수정을 맡겼더니, 수정 전과 후의 IoU가 평균 0.9 수준이라고 합니다. 이정도면 상당히 훌륭한 것 같습니다.

Results
결과는 한마디로 기가 막힙니다. 물론 이 모델을 데이터 레이블링에 쓰고자 한다면 또 다른 수준의 이야기겠지만 무엇보다 zero-shot 이라는 점에서 활용도가 어마어마할 것 같습니다.

그리고 또한 기존의 다른 Interactive Segmentation과의 비교 또한 잊지 않았는데요, 삼성에서 발표했던 RITM과 비교했을 때 전체적으로 매우 월등한 수준을 보여줍니다. 그림 (a)에서 가장 하단에 있는 GTEA 데이터셋은 Georgia Tech Egocentric Activity Datasets으로, 1인칭 시점으로 daily activity를 촬영한 데이터셋입니다. 성능이 유독 저조해서 뭔지 봤더니 별 특이점을 찾지 못했습니다...

이 밖에도 몇가지 디테일이 존재하는데 짧게만 설명하면
- The model was trained for 3-5 days on 256 A100 GPUs
- The image encoder takes ~0.15 seconds on an NVIDIA A100 GPU
- The prompt encoder and mask decoder take ~50ms on CPU in the browser using multithreaded SIMD execution
- The image encoder has 632M parameters
- The prompt encoder and mask decoder have 4M parameters
Conclusion
이 모델은 스스로를 'Foundation Model for Image Segmentation'이라고 불렀고, 그럴 자격이 있는 것 같습니다. 더군다나 한번 Image embedding을 얻은 후에는 prompt를 통해 아주 빠르고 자유롭게 마스크를 만들 수 있으니 활용성까지 잡았습니다. 조만간 직접 개발해서 써보고 그 후기를 말씀드릴 수 있으면 좋겠습니다.
'기술 이야기 > 논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] VideoMAE - Masked Autoencoders are Date-Efficient Learners for Self-supervised Video Pre-Training (0) | 2023.04.18 |
|---|---|
| [논문 리뷰] Consistency Models 리뷰 (4) | 2023.04.13 |
| [논문 리뷰] Graph Convolutional Network (GCN) (0) | 2023.03.30 |
| [논문 리뷰] Mixed Precision Training (MP, AMP) (0) | 2023.03.29 |
| [논문 리뷰] Recurring the Transformer for Video Action Recognition (0) | 2023.03.28 |




댓글