오늘은 모델의 파라미터를 32-bit가 아닌 16-bit로 표현하여 배치 사이즈를 늘리고, 그에 따라 학습 속도를 빠르게 할 수 있는 Mixed Precision Training이라는 기술에 대해 설명하도록 하겠습니다. 더불어, 이 과정에서 발생할 수 있는 문제를 Adaptive 방식으로 해결하는 과정과 나아가 Automatic Mixed Precision(AMP)이 뭔지 다루도록 하겠습니다.
혹시 논문부터 읽고 싶으신 분은 Mixed Precision Training을 참고하세요
Mixed Precision의 배경
Single Precision(Floating Point 32, FP32)는 과연 딥러닝 학습에서 양보할 수 없는 선일까? 만약 Half Precision(Floating Point 16, FP16)을 활용할 수 있다면 모델 학습에 필요한 메모리도 줄이고, 연산도 가속시킬 수 있습니다. 물론 그렇게 학습된 모델의 성능이 FP32와 비교해서 크게 떨어지지 않아야겠죠.
단순하게 보면 모델의 파라미터를 32-bit에서 16-bit로 줄인 것 뿐이지만, 이 기술은 아래 세가지 측면을 고려했을 때 정말 획기적이라고 말할 수 있습니다.
- 같은 모델이라도 더욱 빠른 학습을 통해 빠르게 결과를 얻을 수 있음
- 빠른 학습, 그에 따른 적은 GPU 사용량이 이산화탄소 배출 저감으로 이어짐
- 모델 구조에 구애받지 않고 모든 모델에 적용될 수 있음
저는 특히 2, 3번이 인상적이었는데요, 그 이유는 특정 모델이나 연산에 국한하지 않고 범용적으로 적용될 수 있으니 이산화탄소 발생으로 인한 환경 파괴를 크게 줄일 수 있기 때문입니다. 더욱이 요즘은 GPT, 특히 ChatGPT로 대표되는 많은 초거대 AI 모델이 득세하고 있기 때문에 그것들을 학습할 때 사용하는 자원이 천문학적임을 고려한다면 Mixed Precision의 중요성은 이루 말할 수 없을 것 같습니다.
Half Precision의 문제점
생각해보면 파라미터를 32-bit에서 16-bit로 줄여 숫자의 표현 정밀도를 낮춰 연산량을 줄이고 학습 속도를 높일 수 있다면 처음부터 16-bit로 하면 되는게 아닐까? 하는 생각을 할 수 있습니다.
그래서 살펴본 아래 자료에서 대답을 찾을 수 있습니다. 아래 그림은 NVIDIA Technical Blog에서 실험한 Object Detection에서 유명한 SSD(Single Shot Multibox Detector)모델의 파라미터가 가진 gradient의 분포입니다.
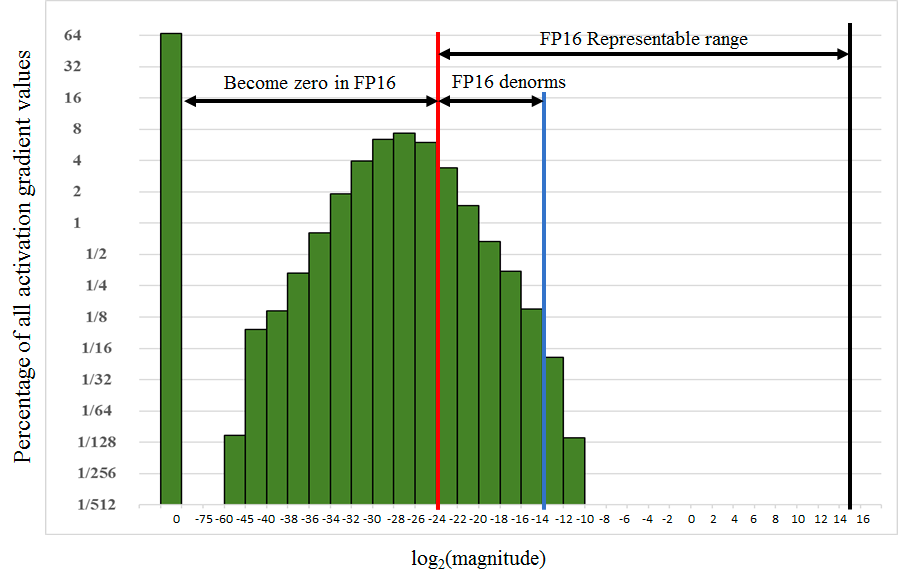
그림의 빨간색 선을 기준으로 왼쪽은 FP16으로는 표현할 수 없는 숫자 범위이고 오른쪽은 FP16으로 표현 가능한 수의 범위입니다. 절반 이상의 gradient가 FP16으로는 표현할 수 없기 때문에 FP16으로 학습을 한다면 많은 정보가 소실될 것으로 유추할 수 있습니다.
이것은 bit 수에 따른 수의 표현 범위가 크게 차이나기 때문인데요, “bit 수가 절반이 된다고 뭐가 그렇게 차이나겠어?”라고 생각하시는 분은 아래의 자료를 보시면 금방 이해하실 수 있습니다.

32-bit와 16-bit는 위의 그림처럼 표현할 수 있는 범위가 극명하게 차이를 보입니다.
혹시나 16-bit도 모자라 8-bit, 4-bit로 학습할 수 있지 않을까하는 욕심은 과유불급…
때문에 FP16을 활용해서 메모리와 속도의 이점을 가져가고 싶지만 위와 같은 문제로 Fully Designed to FP16 모델은 성능 저하가 명백해 보입니다. 이를 막기 위해 Mixed Precision이 제안되었습니다.
참고로 C에서는 FP16을 지원하지 않기 때문에 CPython 기반인 Numpy를 활용해도 16-bit / 32-bit 속도 차이가 없다는 내용이 보고된 바 있습니다. 오히려 16-bit가 더 느려졌다는 내용도 있었지만 이 부분은 해결된 것으로 보입니다.
방법
이름처럼 모든 파라미터를 FP32로 하지도, FP16으로 하지도 않습니다. 두 타입을 넘나들며 학습을 수행하게 되며 논문에서 소개된 그림은 아래와 같습니다.

Mixed-Precision Training Iteration (Version 1)
- FP32로 표현된 FP32 Master weights을 복사하여 FP16 weights를 만든다
- FP16으로 Forward Propagation 진행 (gradient는 FP16일 것)
- Loss 값을 Scale factor S로 곱한다
- 얻은 FP16 gradient를 Backpropagate 한다
- 3번에서 Loss를 S로 곱했으니 Backprop해서 얻은 weight gradient에 S를 나눈다
- Gradient clipping, weight decay 등을 적용한다
- FP32 Master weights을 업데이트한다
그런데 Scaling factor S가 너무 크거나 작으면 곱하고 나누는 과정에서 Inf 또는 NaN이 발생할 수 있습니다. 이 세상엔 너무나 많은 모델이 있고 실험 환경이 있는데, S를 늘 같은 값으로 정해 학습하는 것은 좋은 방법이 아닌 것 같죠.
다만 생각할 수 있는 것은 gradient의 최댓값이 65,504 (FP16의 최댓값)을 넘지 않도록 설계하는 것입니다. 따라서 초기 S를 크게 설정하되 iteration이 지나서 학습에 문제가 발생하면 S를 키우거나 줄이거나 하는 방법을 선택하면 좋을 것 같고 우리는 이 방법을 Adaptive라고 표현할 수 있겠습니다. 그리고 이걸 알고리즘으로 설명하면,
Mixed-Precision Training Iteration (Version 2)
- FP32로 표현된 FP32 Master weights를 저장해둔다
- S의 초기값을 큰 수로 설정한다
- 매 iteration 마다 아래를 수행:
- FP32 weights을 복사하여 FP16weights을 만든다.
- Forward propagation 수행
- Loss 값을 Scale factor S로 곱한다
- Backward propagation 수행
- 만약 모델 전체 weight의 gradient 중에서 하나라도 inf 또는 NaN이 발생한다면:
- S값을 줄인다.
- Weight update를 하지 않고 다음 iteration으로 넘어간다 (f, g, h 건너뜀)
- backprop해서 얻은 weight gradient를 S로 나눈다
- Gradient clipping, weight decay를 포함하여 weight update 수행
- 만약 최근 N iteration 동안 inf또는 NaN이 발생하지 않았다면 S값을 증가시킨다
귀찮아서 영어를 그대로 옮겼지만 쉽게 이해할 수 있다. 단지 Inf 또는 NaN이 발생했을 경우 S를 키우거나 줄인다는 점이 추가되었다.
- 왜 S값을 키우나요?
- S를 곱한다는 의미는 위의 gradient histogram 그림에 있는 모든 막대기를 오른쪽으로 이동시킨다는 의미입니다. 아까 빨간색 선 오른쪽으로는 16-bit로 표현할 수 있는 범위라고 했으므로, 최대한 많은 파라미터를 빨간색 선 오른쪽으로 이동시키는 것이 이 방법의 핵심이기 때문입니다. (정확히는 맨 오른쪽 검은색 선과 중앙의 빨간색 선 그 사이에 최대한 많은 gradient를 분포시키는 것이 목표)
참고로 PyTorch에서는 GradScaler(S)의 초기값이 65536.0으로 설정되어 있습니다.

결과
Mixed Precision을 이용해서 학습했을 경우 성능의 저하는 없고 throughput은 1~5배 증가한 것을 실험을 통해 확인할 수 있습니다.
보고된 숫자는 표에 나와있고, 제 의견을 덧붙이자면
- 혹자들은 Mixed Precision을 활용했을 때 오히려 성능이 더 증가하는 경우도 있다고 말하지만 제 생각엔 보고된 차이는 오차 범위 내에 있다고 생각합니다. 같은 모델, 같은 데이터셋이라도 성능이 달라질 요인은 몇가지 있기 때문에 (데이터 순서, 모델 초기값)위와 같은 수준의 차이는 무시 가능한 것 같습니다.
- MXNet Framework에서 성능 향상이 눈에 띄었는데 이유는 좀 더 생각이 필요합니다.
- bit 수는 절반이 됐는데 throughput은 왜 2배가 되지 않은 경우가 많은 이유는 학습 과정에서 파라미터의 형변환 및 프레임워크 자체의 오버헤드가 존재하기 때문이라고 추정됩니다.
추가 사항
AllowList, DenyList, InterList
왜 이런 구분이 있는 것일까? 원문과 함께 살펴보겠습니다.
- How is AllowList/DenyList/InferList determined? What are the corresponding ops that are in each list?
- We determine these based on our experience with numeric stability from our research. AllowList operations are operations that take advantage of our GPU Tensor Cores. DenyList operations are operations that may overflow the range of FP16, or require the higher precision of FP32. InferList operations are operations that are safely done in either FP32 or FP16. Typical ops included in each list are:
- AllowList: Convolutions, Fully-connected layers
- DenyList: Large reductions, Cross entropy loss, L1 Loss, Exponential
- InferList: Element-wise operations (add, multiply by a constant)
- We determine these based on our experience with numeric stability from our research. AllowList operations are operations that take advantage of our GPU Tensor Cores. DenyList operations are operations that may overflow the range of FP16, or require the higher precision of FP32. InferList operations are operations that are safely done in either FP32 or FP16. Typical ops included in each list are:
주목할 점은 DenyList인데, 먼저 이것을 두 분류로 나눠보면
- Linear operation: Large reductions, L1 Loss
- Non-linear operation: Cross entropy loss, Exponential
Non-linear는 log 또는 e 등의 지수연산이 들어가기 때문에 쉽게 FP16의 표현 범위를 넘어갈 것으로 예상할 수 있습니다. 따라서 Mixed Precision 적용 시 형변환을 하면 성능 저하가 발생할 것이 뚜렷합니다.
하지만 Linear는 조금 가능성이 낮아보이는데, 왜냐하면 단순 사칙연산에 해당하기 때문입니다. 그래도 생각해보자면 L1 Loss는 mean 또는 sum 연산이 옵션으로 존재하는데, 아마도 Large mini-batch를 가정했을 때 성능 저하가 발생할 것으로 예상할 수 있습니다 (많은 수를 더하는 과정에서 범위를 벗어날 수 있기 때문이라고 이해했습니다).
Automatic Mixed Precision(AMP)는 무엇인가?
- What is Automatic Mixed Precision (AMP) and how can it help with training my model?
- Automatic Mixed Precision (AMP) makes all the required adjustments to train models using mixed precision, providing two benefits over manual operations:
- Developers need not modify network model code, reducing development and maintenance effort.
- Using AMP maintains forward and backward compatibility with all the APIs for defining and running models.
- Automatic Mixed Precision (AMP) makes all the required adjustments to train models using mixed precision, providing two benefits over manual operations:
정리하자면 Mixed Precision을 쉽게 적용할 수 있게끔 프레임워크 차원에서 제공하는 것을 의미합니다.
결론
오늘 Mixed Precision에 대해 소개드렸는데, 이 기술은 AI 서비스를 제공하는 회사에게 매우 중요한 내용이라고 생각합니다. 그 이유는 딥러닝 모델을 학습할 때 비용적, 시간적 자원이 정말 많이 들어가기 때문입니다. 대충 어림계산을 해도 모델 학습에 필요한 시간을 절반으로 줄일 수 있다면 그것에 필요한 물적 비용 또한 절반이 되고, 서비스 개발 속도도 큰 폭으로 개선시킬 수 있습니다.
다음에는 PyTorch에서 AMP를 어떻게 사용하는가에 대해 https://pytorch.org/docs/stable/amp.html 를 바탕으로 실습하는 시간을 가져보도록 하겠습니다.
참고자료
https://hoya012.github.io/blog/Mixed-Precision-Training/
Mixed-Precision Neural Networks - A Survey
https://developer.nvidia.com/blog/mixed-precision-training-deep-neural-networks/
NVIDIA - Train with Mixed Precision
https://pytorch.org/blog/what-every-user-should-know-about-mixed-precision-training-in-pytorch/
'기술 이야기 > 논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] VideoMAE - Masked Autoencoders are Date-Efficient Learners for Self-supervised Video Pre-Training (0) | 2023.04.18 |
|---|---|
| [논문 리뷰] Consistency Models 리뷰 (4) | 2023.04.13 |
| [논문 리뷰] Segment Anything 설명 (코드 살짝 포함) (5) | 2023.04.09 |
| [논문 리뷰] Graph Convolutional Network (GCN) (0) | 2023.03.30 |
| [논문 리뷰] Recurring the Transformer for Video Action Recognition (0) | 2023.03.28 |




댓글