안녕하세요, 오늘은 대부분이 알고 계실 ChatGPT와 이번에 공개된 GPT-4의 특징을 살펴보고 어떤 차이가 있는지, 그리고 아직까지 풀지 못한 문제는 무엇인지 짧게 설명하도록 하겠습니다.
ChatGPT의 파급력
OpenAI는 ChatGPT를 공개해서 세상을 깜짝 놀라게 했습니다. 물론 LLM(Large Language Model)이라는 분야에서 GPT-1부터 꾸준히 연구를 진행한 끝에 얻은 결과물이지만 필자도 정말 많이 놀랐습니다. AI의 발전이 이렇게 빠르게 이루어질 줄이야…
언어가 필요한 모든 분야에 적용될 수 있을만큼 성능이 대단했는데, 단순한 대화를 넘어 각종 전문 분야에서도 막힘이 없고 유머와 같이 창의성이 필요한 내용에서도 사람들을 놀라게 했습니다. 실제로 다양한 분야에서 ChatGPT를 도입하여 새로운 서비스를 만들어냈습니다(심지어 이 서비스를 만들기 위해 필요한 기획, 코딩 등도 ChatGPT의 힘을 빌렸다는 이야기가 들립니다). 한편으로는 해킹이나 언어폭력과 같은 비윤리적 활용 사례도 들리는 등 사회적으로 많은 이야기를 낳았습니다.
저 또한 ChatGPT와 많은 이야기를 나눴는데 딱딱한 말투만 좀 고친다면 아주 박식한 실제 사람과 대화한다는 느낌마저 받았습니다.
ChatGPT와 GPT-4
이렇게 훌륭한 ChatGPT의 후속작으로 나온 GPT-4는 기존과 무엇이 같고 무엇이 다를까요?
학습 방법 차이
둘은 기본적으로 GPT라는 이름을 달고 나오기에 구조에서 큰 차이가 없습니다. 그동안의 GPT 역사를 파악하면 알 수 있는 부분은 버전이 올라갈수록
- 모델 구조에 약간의 수정이 있었고
- 더 정교하게 학습 방법을 설정했으며
- 더 많은 수의 레이어를 쌓아 모델 사이즈가 기하급수적으로 증가
했습니다.
GPT는 Transformer 구조를 이해하신다면 이야기가 더 쉬워지는데, 일단 입력을 받으면 하나씩 순차적으로 말을 내뱉는 decoder-only 구조를 갖고 있습니다(일단 뭐든 간에 말을 뱉고 그다음 말을 생각합니다). ChatGPT와 GPT-4는 아마도 이 구조를 벗어나지 않았을 것으로 추정됩니다.
두 모델 모두 위에서 말한 구조의 네트워크를 엄청나게 많은 텍스트로 학습합니다. 우리는 이 과정을 Pre-training이라 부르고, 그다음 모델의 디테일을 살리는 지도 학습(Supervised Learning)을 수행합니다. 보통 Pre-training을 마친 모델을 재학습하는 과정을 Fine-tuning 한다고 표현합니다. 정리하자면,
- 수많은 텍스트를 통해 모델을 Pre-training (비지도 학습, unsupervised learning)
- 정답이 있는 데이터를 통해 모델을 Fine-tuning (지도 학습, supervised learning)
ChatGPT
ChatGPT(GPT-3.5)의 학습 과정은 일단 수많은 데이터셋으로 GPT 구조를 Pre-training 했다는 것을 전제로 아래와 같은 과정을 거칩니다.
- 질문(Query)에 대해 정답 예시가 있는 데이터셋으로 GPT를 학습 (데이터셋은 사람이 직접 만듦)
- 이제 하나의 질문을 넣으면 모델이 여러개의 답변을 내놓도록 설계
- 여러 개의 답변을 두고 사람이 랭킹을 매김
- 매겨진 랭킹을 기반으로 강화학습(Reinforcement Learning) 수행

랭킹을 활용해서 어떤 방식으로 강화학습의 손실함수를 설계하는지는 모르겠지만 위와 같이 사람이 직접 강화학습에 참여하는 방식을 RLHF(Reinforcement Learning from Human Feedback)이라고 부릅니다.
GPT-4
그럼 GPT-4는 어떻게 학습될까요? 사실 구체적인 방법은 공개되지 않았습니다. 다만 비슷한 구조를 갖고 Multimodal 학습을 한다는 정도는 유추할 수 있습니다. 한편 RLHF가 조금 더 개선됐는데, 답변이 조금 더 정확해지고 Safety guardrails을 보다 잘 지키는 방향으로 학습됐다고 합니다.
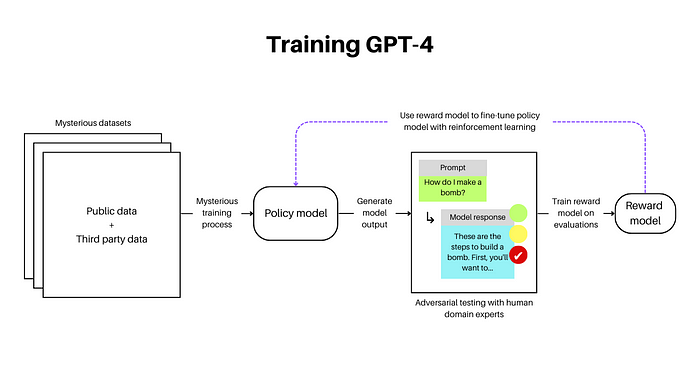
그리고 ChatGPT와는 달리 adversarial training을 진행했는데, 이건 아까 언급한 safety guardrails과 관련이 깊어 보입니다. ‘폭탄 만드는 방법 알려줘’와 같이 악의적인 문장을 질문으로 넣고 모델이 정말 폭탄 만드는 방법을 설명하면 앞으로는 이러한 답변을 하지 않게끔 학습하는 방식입니다. 이런 학습을 위해 50명이 넘는 전문가가 오랜 기간을 학습 과정에 참여했다고 합니다.
성능 차이
OpenAI에 의하면 두 모델 간 성능차이는 어찌 보면 미미하다고 볼 수 있습니다. 모델의 사이즈나 데이터셋 사이즈보다도 언급한 adversarial training이 더 중요한 건 아닐까요? 윤리적으로 위험할 것 같은 답변을 많이 피하게 된 것만으로도 충분한 진보인 것처럼 보입니다. 그래도 두 모델의 성능 차이를 비교하자면,

각 시험에 대해 엎치락뒤치락 하는 것 같지만 GPT-4의 점수가 더 낮은 경우는 차이가 미미한데 높은 경우는 ChatGPT를 크게 앞서는 것 같습니다. 전반적으로 GPT-4의 시험 성적이 더 좋은 것을 확인 가능합니다. 게다가 GPT-4는 Multimodal을 지원하기 때문에 전작과의 비교가 무색합니다.
또 위에서 Safety guardrails를 언급했었죠? 물론 엄밀히는 안전과 관련은 없지만 아래의 결과를 보면 재밌습니다.
 |
 |
궁예라는 선수는 MLB에 없었을텐데 ChatGPT는 아주 당당하게 MVP 수상 선수를 소개했습니다. 반면 GPT-4는 없는 건 없다고 잘 대답하는 것을 보면, 허무맹랑한 답변을 내놓게 하지 않기 위해 많은 노력을 했음을 알 수 있습니다.

물론 아직도 가야할 길이 멀었다고 생각합니다. 생각해 보면 우리 인간은 모르면 모른다고 대답할 것 같은데 GPT 시리즈는 뭔가 말을 내뱉고 봅니다. 이런 케이스를 하나하나 학습시키는 일은 굉장히 어려울 것 같습니다.
하나만 더 보여드리고 넘어가겠습니다.

Multimodal
ChatGPT에서는 지원하지 않던 Multimodal이 이번에는 적용되었습니다. 현재까지는 이미지를 이해하는 능력이 소개되고 있습니다.

위의 예시는 GPT-4 Technical Report에서 발췌했는데요, 놀라운 점은
- 이미지의 구도(panel by panel)를 이해
- 이미지 내 객체, 상황을 모두 이해
- 유머를 이해
참 대단하지 않나요??
한계점
큰 개선이 있었음에도 불구하고 아직까지 지적되는 문제는 있습니다.
- 허무맹랑한 답변 (사실이 아닌)
- 욕설, 차별, 성적인 표현과 같은 유해한 답변을 아직까지도 함
- 소외 계층에 대한 강한 고정관념
등이 거론되는 주요 문제인데, 이는 더욱 더 많은 데이터를 통해 학습해야만 해결될 것 같습니다.
감사합니다
'기술 이야기 > AI 소식' 카테고리의 다른 글
| [AI 소식] 베지 쉑(Veggie Shack) - 쉑쉑(Shake Shack)버거 AI 신메뉴 (0) | 2023.05.05 |
|---|---|
| [AI 소식] Midjourney v5로 만든 사람의 노화 과정 (0) | 2023.04.01 |


댓글